
티스토리 뷰
* 이 글은 공부하는 단계에서 샘플을 이해하고 개인적인 해석이 들어가 있으므로 잘못된 내용이 있을수 있습니다.
이번에는 Custom Dataset(balloon) 을 이용한 모델 훈련 예제를 실행해본다.
먼저 ballon_dataset 을 다운받아서 압축을 풀어준다.
wget https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
unzip ballon_dataset.zip폴더 안에는
train 전용 이미지들과 validation 용 이미지들이 각각 폴더에 있고
풍선에 레이블링이 된 json파일이 있다.
아래 코드는 detectron zoo 모델에 커스텀 데이터 세트(balloon) 를 등록하고 확인하는 코드이다.
test.py 라는 파일을 만들고 다음 코드를 넣고 실행해본다.
from detectron2.structures import BoxMode
from detectron2.utils.logger import setup_logger
from detectron2.utils.visualizer import Visualizer
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
from detectron2.data import MetadataCatalog, DatasetCatalog
im = cv2.imread("./input.jpg")
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
dataset_dicts = get_balloon_dicts("balloon/train")
for d in random.sample(dataset_dicts, 3):
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
out = visualizer.draw_dataset_dict(d)
cv2.imshow("image", out.get_image()[:, :, ::-1])
cv2.waitKey(0)
cv2.destroyAllWindows()Colab 에서 실행한것과 동일하게 결과가 나오는것을 확인할수 있다.

본격적으로 트레이닝을 시켜본다.
위의 코드에서 이미지를 랜덤하게 추출하는 부분 코드를 주석 처리하고 다음 코드를 추가로 삽입한다.
( 트레이닝 코드를 추가하면, 메인 모듈이 아닌 경우 런타임 에러가 나오기 때문에 코드를 아래와 같이 변경해야한다. )

from detectron2.structures import BoxMode
from detectron2.utils.logger import setup_logger
from detectron2.utils.visualizer import Visualizer
setup_logger()
# import some common libraries
import numpy as np
import os, json, cv2, random
from detectron2.data import MetadataCatalog, DatasetCatalog
im = cv2.imread("./input.jpg")
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
if __name__ == '__main__':
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
dataset_dicts = get_balloon_dicts("balloon/train")
# for d in random.sample(dataset_dicts, 3):
# img = cv2.imread(d["file_name"])
# visualizer = Visualizer(img[:, :, ::-1], metadata=balloon_metadata, scale=0.5)
# out = visualizer.draw_dataset_dict(d)
# cv2.imshow("image", out.get_image()[:, :, ::-1])
# cv2.waitKey(0)
# cv2.destroyAllWindows()
from detectron2.engine import DefaultTrainer
from detectron2 import model_zoo
from detectron2.config import get_cfg
cfg = get_cfg()
# without cuda
cfg.MODEL.DEVICE = "cpu"
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ()
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Let training initialize from model zoo
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025 # pick a good LR
cfg.SOLVER.MAX_ITER = 300 # 300 iterations seems good enough for this toy dataset; you will need to train longer for a practical dataset
cfg.SOLVER.STEPS = [] # do not decay learning rate
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()
Colab 에서는 GPU를 이용해 2분이 걸렸지만, CPU로 training 을 하다보니 1시간 18분이라는 시간이 걸렸다.
하이퍼 파라메터를 변경해봐야 겠지만, 우선 전체적인 흐름과 사용법을 익히기 위해 기본 샘플 그대로 실행을 해본다.

트레이닝이 완료되면 output 폴더에 다음과 같이 파일이 생성된다.
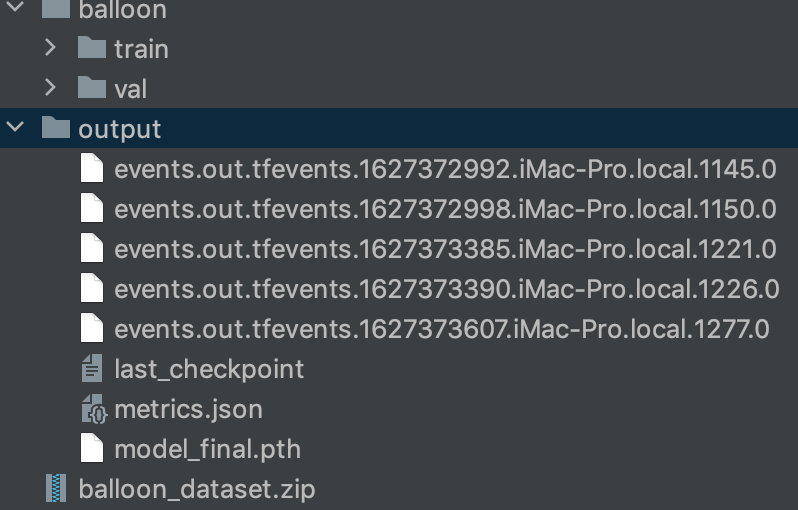
최종 트레이닝 결과물이 model_final.pth 에 저장이 되는것으로 보인다.
이제, 훈련결과물을 가지고 검증을 해볼 차례이다.
Colab 에서는 기존의 코드를 가지고 계속 사용하기 때문에 실제 활용을 할때 불필요한 코드를 가져가게 된다.
따라서 새로 파일을 만들어서 검증을 해보도록 한다.
test2.py 라는 파일을 만들고 다음의 코드를 넣고 실행해본다.
import numpy as np
import os, json, cv2, random
from detectron2 import model_zoo
from detectron2.structures import BoxMode
from detectron2.config import get_cfg
from detectron2.engine import DefaultPredictor
from detectron2.utils.visualizer import ColorMode
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
if __name__ == '__main__':
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
cfg = get_cfg()
# without cuda
cfg.MODEL.DEVICE = "cpu"
cfg.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128 # faster, and good enough for this toy dataset (default: 512)
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # only has one class (ballon). (see https://detectron2.readthedocs.io/tutorials/datasets.html#update-the-config-for-new-datasets)
# NOTE: this config means the number of classes, but a few popular unofficial tutorials incorrect uses num_classes+1 here.
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth") # path to the model we just trained
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 # set a custom testing threshold
predictor = DefaultPredictor(cfg)
dataset_dicts = get_balloon_dicts("balloon/val")
for d in random.sample(dataset_dicts, 3):
im = cv2.imread(d["file_name"])
outputs = predictor(im) # format is documented at https://detectron2.readthedocs.io/tutorials/models.html#model-output-format
v = Visualizer(im[:, :, ::-1],
metadata=balloon_metadata,
scale=0.5,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels. This option is only available for segmentation models
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
print(outputs)
cv2.imshow("image", out.get_image()[:, :, ::-1])
cv2.waitKey(0)
cv2.destroyAllWindows()

output 의 결과는 다음과 같다.
{'instances': Instances(num_instances=3, image_height=768, image_width=1024, fields=[pred_boxes: Boxes(tensor([[664.5765, 1.5540, 912.3661, 258.9362],
[364.6794, 1.9076, 572.2790, 223.7474],
[143.4272, 8.6358, 385.4707, 245.0285]])), scores: tensor([0.9951, 0.9943, 0.9771]), pred_classes: tensor([0, 0, 0]), pred_masks: tensor([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]])])}풍선 instance 의 결과 갯수과 이미지 정보, 그리고 instances box 좌표와 사이즈 정보, score( 확률 )가 있다.
실제 활용시에 무언가를 찾는다면 위의 정보만 가지고 충분히 활용할수 있다.
그런데 Colab 의 결과와 다른점이 하나 있다.
풍선이 아닌것도 78% 가 나왔다는점이다.

Colab의 코드에서 cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7 를 0.5 로 변경하고 다시 확인해보았다.

10% 이상 차이가 나는것은 결과게 큰 영향을 줄것같다.
다음번에는 현재 CPU환경에서 맞게 하이퍼 파라메터를 수정하고 다시 트레이닝을 해볼 필요가 느껴졌다.
추가로, 검증 모듈이 있는데 Colab 에서는 에러가 난다.
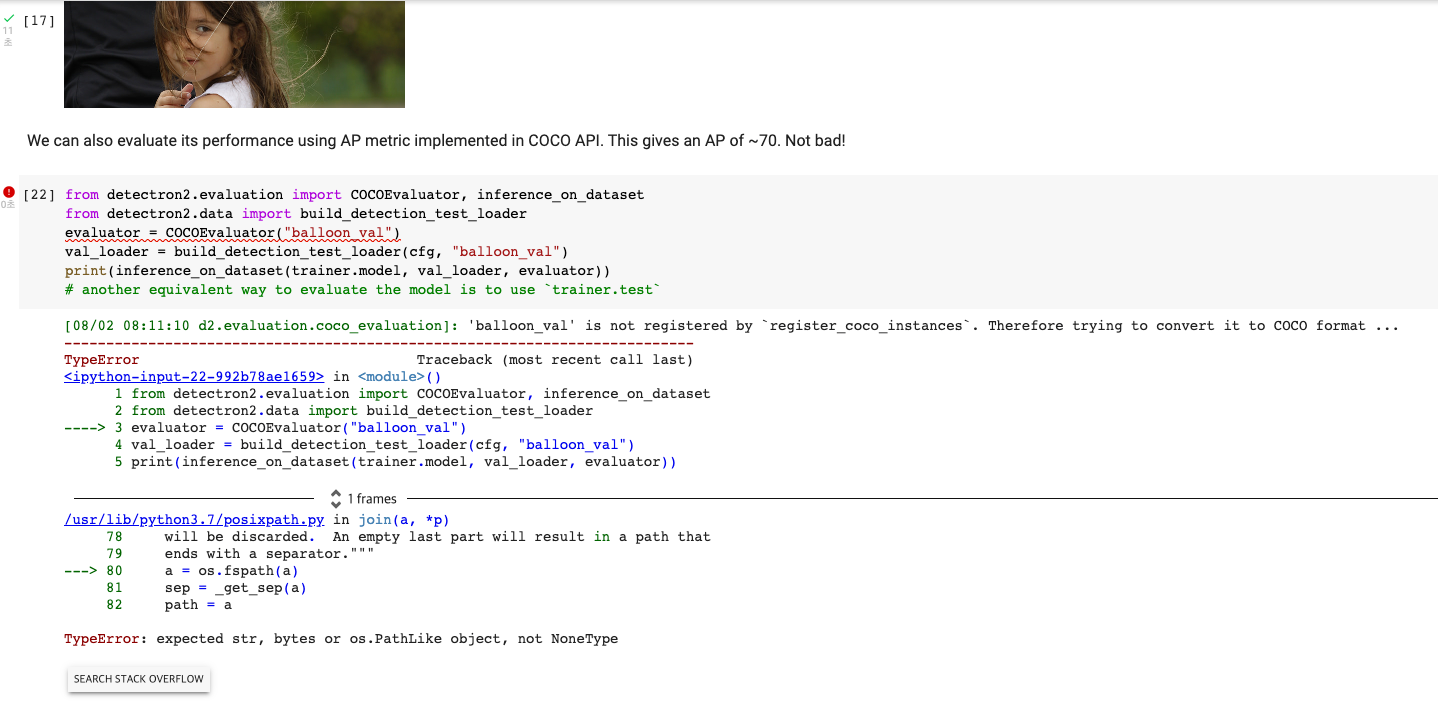
3번째 evaluator = 라인을 아래와 같이 고치면 된다.
evaluator = COCOEvaluator("balloon_val", ("bbox", "segm"), False, output_dir="./output/")
로컬에서도 테스트를 해보았더니 다음과 같은 결과가 나왔다.

Colab과 조금 다른 결과가 나왔다.
동일한 코드로 트레이닝을 할때마다 조금씩 다른 결과가 나오는것 같다.
무튼, 서버에서 이미지를 직접 눈으로 확인하지 않고도 이렇게 검증을 할수 있는 기능도 제공이 된다.
이로써 Detectron 기본 예제를 따라하기 과정을 마친다.
'Develope > Python' 카테고리의 다른 글
| Detectron - 응용편2 #validation (0) | 2021.08.04 |
|---|---|
| Detectron - 응용편1 #image labeling (0) | 2021.08.04 |
| Detectron2 - Example 따라하기 1 (0) | 2021.07.27 |
| Facebook Detectron2 - 설치 (0) | 2021.07.27 |
| 우분투 python3 설치, pip 에러, pip upgrade 주의사항 (2) | 2019.12.24 |
- Total
- Today
- Yesterday
- 아이폰
- 딥러닝
- IOT
- diy
- 캠핑
- 우분투
- 라즈베리파이
- Deeplearning
- ubuntu
- 공기청정기
- 강좌
- 머신러닝
- swift
- 미세먼지
- 스위프트
- 사물인터넷
- 아두이노
- OpenCV
- Android
- Python
- 서버
- php
- object-C
- mysql
- 엘라스틱서치
- ios
- xcode
- 인공지능
- 파이썬
- 리눅스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |